蚂蚁集团发布全模态大模型Ming-Flash-Omni2.0 引领多模态技术新突破
创始人
2026-02-11 12:04:58
0次
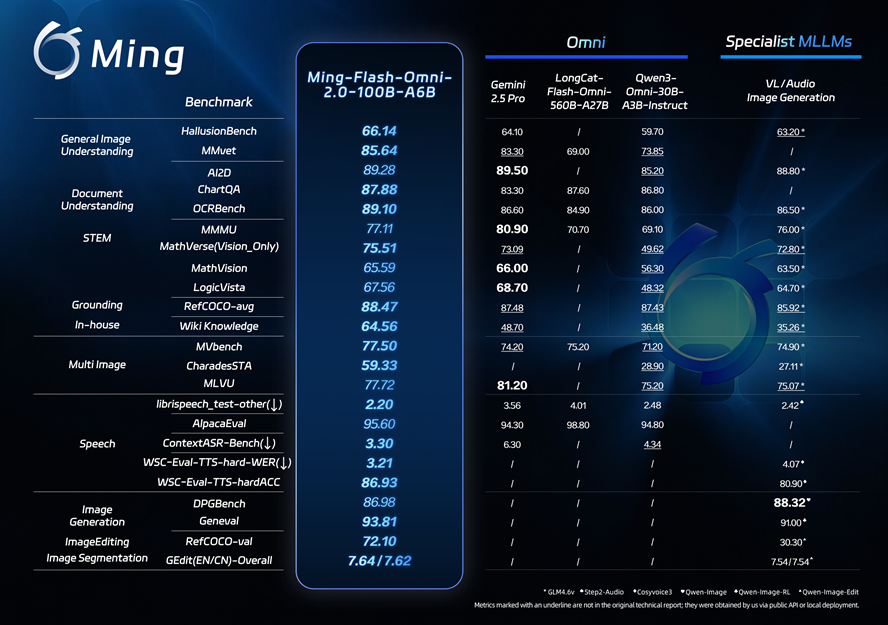
2月11日,蚂蚁集团宣布开源发布全模态大模型Ming-Flash-Omni2.0,该模型在视觉语言理解、语音可控生成、图像生成与编辑等多个领域表现出色。Ming-Flash-Omni2.0是业界首个全场景音频统一生成模型,能够在同一音轨中同时生成语音、环境音效与音乐,用户可以通过自然语言指令精细控制音色、语速、语调、音量、情绪与方言等参数。模型在推理阶段实现了3.1Hz的极低推理帧率,支持分钟级长音频的实时高保真生成,保持了业界领先的推理效率与成本控制。
Ming-Flash-Omni2.0基于Ling-2.0架构(MoE,100B-A6B)训练,全面优化了“看得更准、听得更细、生成更稳”三大目标。在视觉方面,模型融合了亿级细粒度数据与难例训练策略,显著提升了对复杂对象的识别能力;音频方面,实现了语音、音效、音乐同轨生成,并支持自然语言精细控制;图像方面,增强了复杂编辑的稳定性,支持光影调整、场景替换、人物姿态优化及一键修图等功能。百灵模型负责人周俊表示,全模态技术的关键在于通过统一架构实现多模态能力的深度融合与高效调用,开源后,开发者可以基于同一套框架复用视觉、语音与生成能力,降低多模型串联的复杂度与成本。
Ming-Flash-Omni2.0的模型权重、推理代码已在HuggingFace等开源社区发布,用户也可通过蚂蚁百灵官方平台LingStudio在线体验与调用。
相关内容
热门资讯
中国移动发力AI:10亿用户享...
5月6日,第九届数字中国建设峰会期间,中国移动举办了人工智能生态大会。会上,中国移动董事长陈忠岳强调...
比亚迪员工福利大变!园区免费充...
5月6日,比亚迪宣布取消园区内面向员工的免费充电政策,全国所有园区内的交流充电桩、直流充电桩及闪充桩...
本田或无限期搁置加拿大电动汽车...
5月6日,据《日经亚洲》报道,本田汽车正在与加拿大政府就其位于安大略省的电动汽车及配套电池工厂建设进...
“落水车语音助手“哪吒”坚守岗...
近日,贵州一位车主的车辆意外落水,在水中浸泡数小时。令人惊讶的是,车主尝试唤醒车载语音助手“哪吒”,...
宾利电动化战略大调整:裁撤75...
近日,宾利品牌在电动化战略上做出重大调整。新任CEO弗兰克指出,超豪华消费者对纯电车型的接受度不高,...
市场监管总局突破测控装备智能化...
5月6日,市场监管总局联合国内科技力量在装备系统智能化领域取得显著进展。研究团队运用自然语言处理和人...
丰田130亿建印度三厂,目标年...
5月6日,丰田汽车宣布在印度西部马哈拉施特拉邦投资约3000亿日元(约合130亿元人民币)新建三座整...
Rivian拟自产激光雷达,C...
近日,美国电动汽车制造商Rivian的CEO RJ·斯卡林奇透露,公司正在考虑自行生产激光雷达传感器...
华为鸿蒙系统升级:小艺帮记新增...
5月6日,华为鸿蒙HarmonyOS 6.1系统对“小艺帮记”功能进行了更新,新增身份验证和同步收藏...
疲劳驾驶酿大祸!男子信辅助驾驶...
5月5日,杭甬高速宁波方向发生一起因驾驶员过度信任辅助驾驶系统而引发的违规停车事件。一辆黑色SUV在...