0.9B参数GLM-OCR开源!OCR新标杆性能SOTA
创始人
2026-02-03 09:40:57
0次
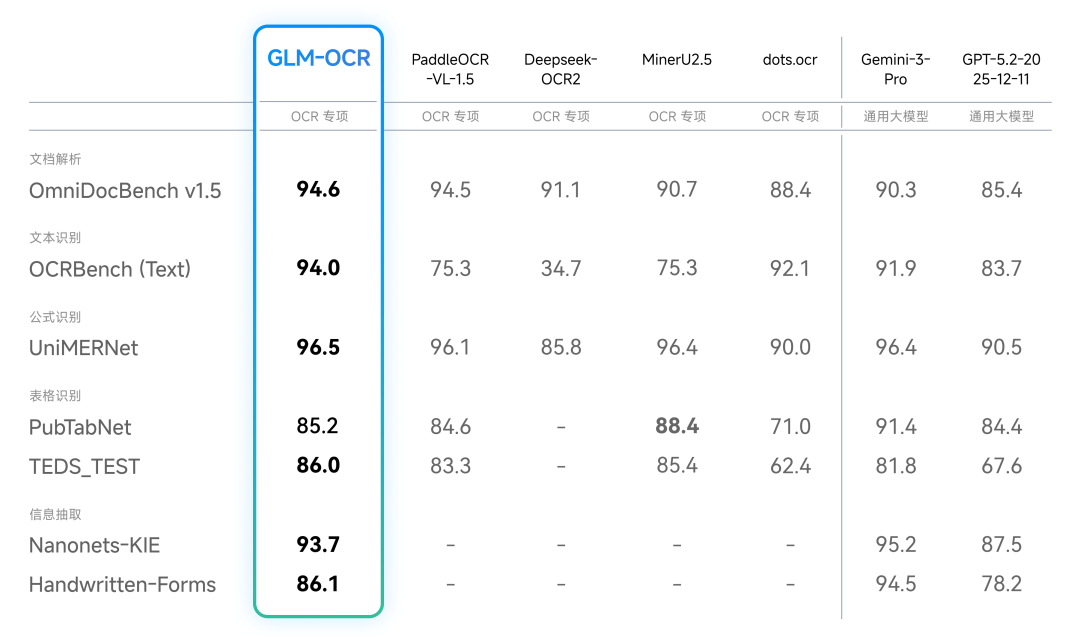
今日,智谱宣布正式发布并开源GLM-OCR,这是一款轻量级的专业级OCR模型,以其“小尺寸、高精度”的特点成为文档解析能力的新标杆。GLM-OCR模型参数规模仅为0.9B,却在多项主流基准测试中取得了SOTA(State of the Art)表现,特别是在公式识别、表格识别和信息抽取方面。该模型针对真实业务中的高难度场景进行了优化,如手写体、复杂表格、代码文档和印章等,表现出色。
GLM-OCR在性能上的优势得益于自研的CogViT视觉编码器和深度场景优化,使其在OmniDocBenchV1.5榜单中以94.6分的成绩登顶。模型在文本、公式、表格识别及信息抽取四大细分领域的表现均优于多款OCR专项模型,性能接近Gemini-3-Pro。此外,GLM-OCR在代码文档、真实场景表格、手写体、多语言、印章识别、票据提取等维度均取得显著优势,展现了其在实际应用中的精准解析能力。
技术细节方面,GLM-OCR采用了“编码器-解码器”架构,由视觉编码器(ViT)、跨模态连接层和语言解码器三大核心模块组成。模型在训练策略上引入了多Tokens预测损失(MTP),以增强损失信号密度并提升模型学习效率。同时,通过全任务强化学习训练,显著提升了模型在复杂文档场景下的整体识别精度与泛化能力。开源方面,GLM-OCR的SDK与推理工具链已同步开源,环境依赖简单,支持快速调用,易于接入现有业务系统。

相关内容
热门资讯
AI安全漏洞曝光:Anthro...
5月6日,安全研究揭示了主打安全的人工智能公司Anthropic的潜在安全漏洞。人工智能红队测试公司...
特斯拉21万辆车因倒车影像延迟...
5月6日,美国国家公路交通安全管理局(NHTSA)宣布,特斯拉将在美国召回超过21万辆电动车,涉及2...
7年低息车贷全面下架,购车压力...
近日,新能源汽车市场出现了一项重大变化,7年超长低息车贷政策全面下架。此前,特斯拉、小米SU7、理想...
商汤科技挑战AI巨头:低成本高...
5月6日,商汤科技联合创始人兼首席科学家林达华透露,公司从DeepSeek获得启发,即便在资金和技术...
承载“广交天下”的国产无人机,...
文/图 羊城晚报全媒体记者 严锦程4月的广州,春潮涌动,珠江之畔的琶洲展馆人声鼎沸,第139届广交会...
以侨引商以侨促贸,助力经济高质...
羊城晚报讯 16日下午,由广东省侨办、广州市人民政府联合主办的“2026侨助广东经济高质量发展推进大...
以微光入眼以澄明观心 傅锡洪:...
文/羊城晚报全媒体记者 王倩图/羊城晚报全媒体记者 钟振彬 方浩四月的中山大学,草木葱茏。在陈寅恪故...
早筛早诊早治“全链条”出击 ...
广州“肿瘤防治宣传周”系列活动启动,全市癌症总体5年生存率提升至49.57%羊城晚报全媒体记者 朱嘉...
广东强对流天气或迎“双休日” ...
羊城晚报讯 记者梁怿韬报道:广东多地在4月17日迎来强对流天气。截至17日17时,多地在白天时段录得...
消费新语|“首展”+“首秀”,...
监制:唐卫彬策划:陈发宝 姜 范统筹:潘笑天 李 劼记者:林语晋拍摄:甄子豪 李丹丹 张博雅 朱轶琳...