3秒语音样本即可合成逼真人声!智谱发布工业级GLM-TTS系统
创始人
2025-12-11 10:40:58
0次
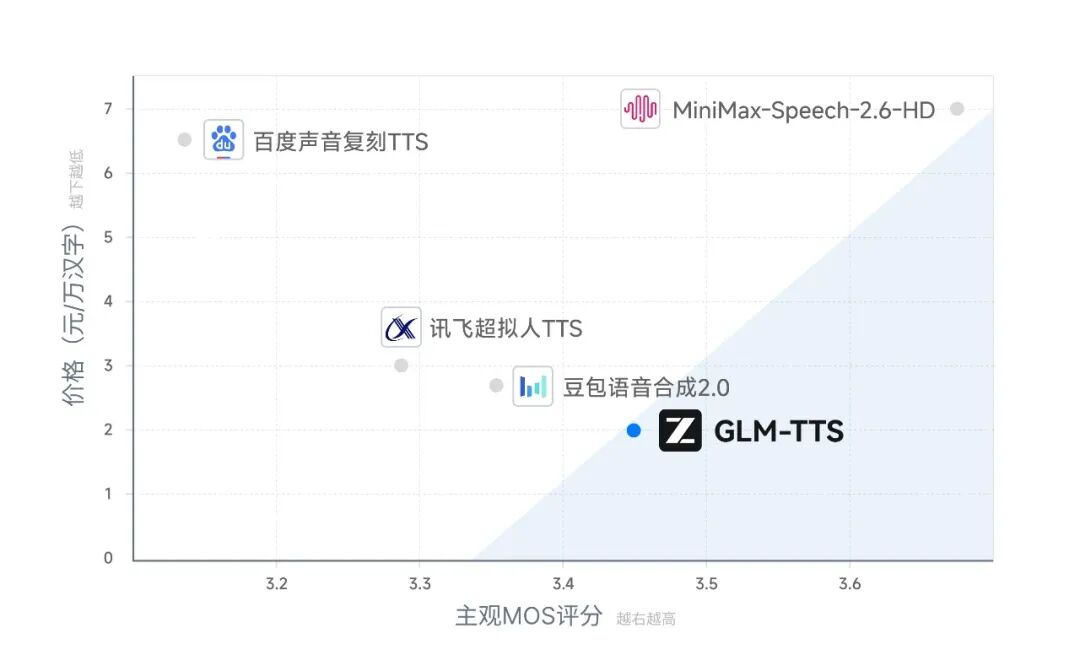
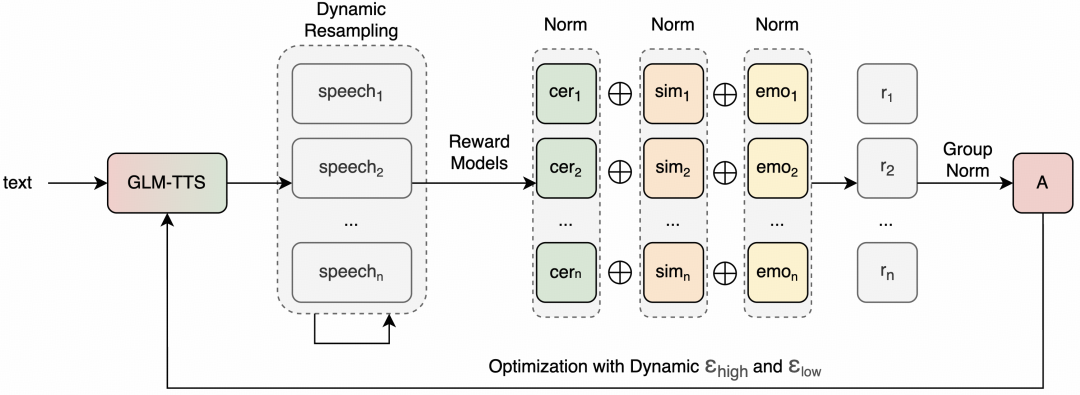
智谱今日发布工业级语音合成系统GLM-TTS,并在HuggingFace和ModelScope上开放模型权重。该系统仅需3秒语音样本即可学习说话人的音色和说话习惯,适用于通用朗读、情感配音等多个场景,实现自然流畅、贴近真人的语音效果。GLM-TTS采用两阶段生成架构,并引入基于GRPO的强化学习方案,在字错误率和情感表达上取得开源SOTA表现。该系统仅使用10万小时训练数据,远低于行业主流商用模型,同时兼顾训练成本和效果,预训练仅需单机4天即可达到开源SOTA水平。
GLM-TTS重点验证了教育、电子书与有声内容、智能客服等场景的应用。在教育场景中,该系统适配多音字和生僻字、公式符号,为教材和题库批量生成标准发音示范音频,并保持大规模合成的一致性和准确度。在电子书与有声内容场景中,GLM-TTS可以用单一音色完成整本书的朗读,也可以为不同角色配置专属音色,适配不同文体的节奏与情绪。在智能客服与语音助手场景中,GLM-TTS能为机器人客服打造温和但克制的声音形象,降低机械感,并与上游NLU/NLG模块协同,支持端到端语音交互。
智谱还开放了GLM-TTS的模型权重、推理代码和在线调用接口,方便开发者、研究者和企业评估与集成。开发者可以在GPU环境中快速部署GLM-TTS,并按需做二次开发。同时,智谱也提供了开放平台和API接口,支持从Demo试用到生产级大规模调用。用户还可以通过网页链接和智谱清言App/网页版快速体验GLM-TTS的合成效果。

相关内容
热门资讯
现代IONIQ V亮相工信部公...
5月10日,现代汽车旗下全新车型IONIQ V(艾尼氪金星)正式出现在工信部第407批《道路机动车辆...
“蔚来李斌24小时直播见证:河...
5月10日,蔚来创始人、董事长兼CEO李斌开启24小时直播,与团队自驾验收河西走廊换电路线贯通。李斌...
北京现代艾尼氪V申报亮相:另类...
5月10日,工信部第407批新车申报目录中,北京现代旗下全新新能源品牌IONIQ(艾尼氪)首款车型—...
特斯拉Model S/X停产,...
5月10日,特斯拉宣布正式停产Model S和Model X两款车型,消费者只能购买库存现车。特斯拉...
吉利银河TT亮相工信部公告,4...
5月10日,工信部发布第407批《道路机动车辆生产企业及产品公告》,吉利银河品牌首款纯电轿跑银河TT...
特斯拉Model S/X签名版...
5月10日,特斯拉宣布推迟原定于5月12日的Model S/X Signature Edition(...
吉利银河TT纯电轿跑申报:5米...
5月10日,工信部第407批新车申报目录中,吉利银河品牌旗下全新纯电车型银河TT正式申报。这款中大型...
专访资深政法记者刘海陵:笔锋铸...
刘海陵的新闻人生,是改革开放的生动缩影,是法治进步的忠实见证,更是新闻理想的永恒传承。世纪之交,香江...
38岁身家过亿房地产老总家中遭...
南京市江宁区一身家过亿的房地产老总刘某,在家中遭人杀害,事发16年后,这处“凶宅”于5月7日进行第二...
粤超第三轮球票今日14时开始预...
随着“五一”小长假结束2026年冠旭电子cleer·广东省城市足球超级联赛(粤超)21城全部亮相5月...