数字人新突破!ViduS1模型实现语音控制视频互动
创始人
2026-07-03 21:51:47
0次
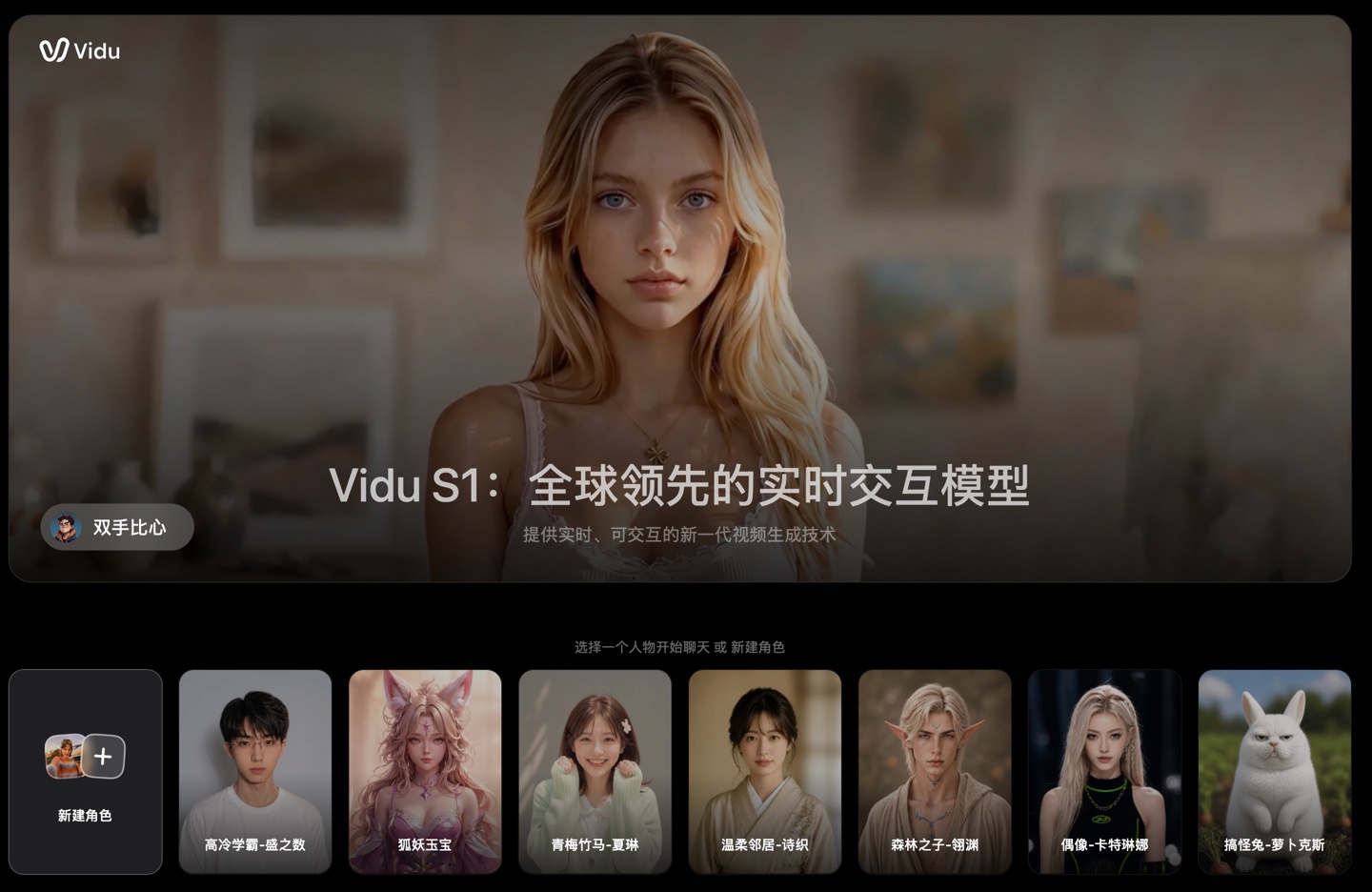
今日,生数科技发布了一款名为ViduS1的新一代实时交互模型,专为实时交互场景设计。该模型支持实时视频通话和语音控制视频走向,允许用户通过语音指令控制数字人的行为,并实现无限时长的连续互动。
ViduS1模型具备540P高清分辨率和25FPS帧率(最高支持42FPS),能够基于用户的初始形象和个性化音色,快速创建专属的交互角色。技术层面,ViduS1采用了自回归扩散模型(AR+Diffusion),不再一次性生成完整视频,而是根据历史画面和当前语音指令及对话上下文,持续预测并生成后续内容。这意味着当用户发出新的语音指令时,模型能够实时理解并调整角色的表情、动作及视频走向,将视频转变为一个持续生成、实时响应、动态演化的交互过程。
目前,ViduS1已开启内测,感兴趣的用户可以通过提供的线上体验地址和API体验地址进行尝试。

相关内容
热门资讯
豆包智能体功能将下线,用户需备...
7月3日,豆包宣布将对其智能体功能进行调整。根据《豆包智能体功能下线通知》,智能体功能将于2026年...
奇瑞星途ES 2027款7月1...
IT之家7月3日消息,奇瑞星途宣布2027款星途ES将于7月12日上市,预售价区间为18.99-21...
领克20三季度上市:800V高...
7月3日,领克汽车销售公司常务副总经理周钘透露,领克20将标配800V碳化硅高压平台及6C补能倍率,...
华境S销量破万!华为技术加持的...
今日,五菱品牌与市场总监思行通过微博宣布,华境S交付量已突破万辆大关。华境S是上汽通用五菱与华为合作...
数字人新突破!ViduS1模型...
今日,生数科技发布了一款名为ViduS1的新一代实时交互模型,专为实时交互场景设计。该模型支持实时视...
路遇小车自燃挺身灭火,广州公交...
6月30日,一辆小车在广州市番禺区市桥地铁站附近发生碰撞后起火,驾车营运至事发现场的广州公交集团下属...
2025年广东城镇单位就业人员...
日前,广东省统计局发布2025年城镇就业人员年平均工资数据。全省城镇非私营单位就业人员年平均工资为1...
广州番禺柏堂村1346套安置房...
文/羊城晚报全媒体记者 陈玉霞日前,随着最后一方混凝土浇筑完成,广州市番禺区化龙镇柏堂村城中村改造项...
全国优秀共产党员赖宣治:扎根偏...
2025年11月9日晚,在万众瞩目的十五运会开幕式点火仪式上,作为唯一的非运动员火炬手,赖宣治手持火...
广州增城首张房票实现“当日领取...
7月1日,广州增城区荔城街举行金星村城中村改造项目房票首发仪式,现场辖区被征收群众朱先生领取了荔城街...