腾讯联合UCLA发布OpenSearch-VL,AI智能体开启多模态深度搜索新时代
创始人
2026-05-07 15:11:18
0次
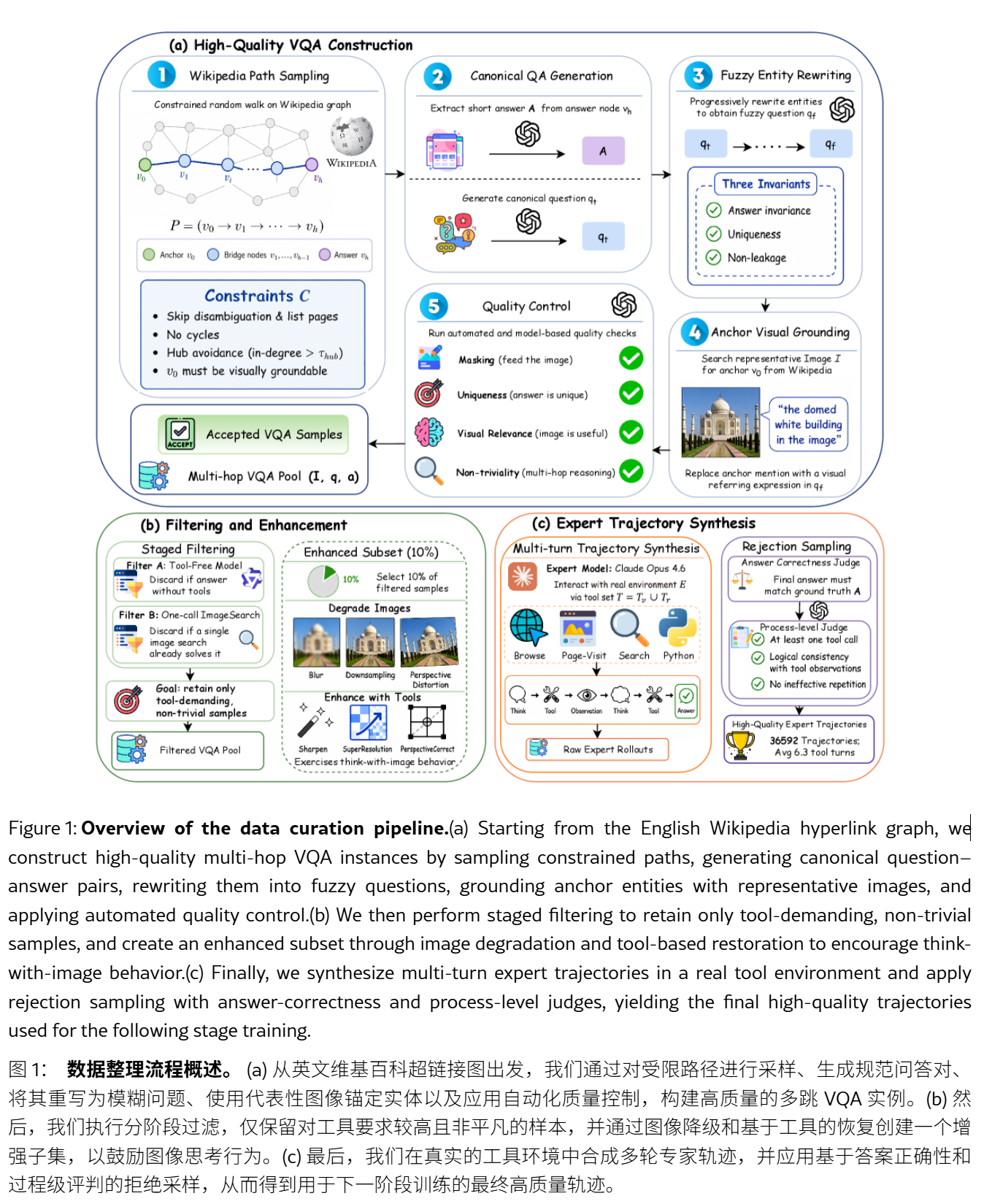
5月7日,腾讯混元(TencentHunyuan)联合加州大学洛杉矶分校(UCLA)、香港中文大学等学府发布了OpenSearch-VL开源多模态训练方案。该方案通过强化学习技术,旨在打造能够处理图像、文本等多种模态输入,并主动调用外部工具进行多步骤推理、证据验证与知识检索的深度搜索智能体。这一研究聚焦于解决知识密集型的复杂视觉问答问题,报告于5月6日在arXiv平台发表。
OpenSearch-VL方案的核心在于构建高质量数据管道,通过维基百科路径采样与模糊实体重写减少检索捷径,产出SearchVL-SFT-36k等数据集。研究团队指出,高质量训练数据是多模态搜索智能体进化的最大瓶颈,而现有顶尖系统的数据来源、过滤标准与工具使用轨迹均属私有,限制了先进能力的复现与系统性研究。因此,OpenSearch-VL提供了从数据、工具到训练算法的完整开源方案,以促进研究发展。
在工具环境方面,OpenSearch-VL不仅包括文本搜索、图像搜索,还整合了OCR、裁剪、锐化、超分辨率与透视校正等功能,使智能体能在查询外部知识前先处理模糊、低分辨率或倾斜的视觉输入。实验结果显示,OpenSearch-VL-30B-A3B模型在VDR、MMSearch等基准上取得了显著增益,平均得分从47.8提升至61.6,消融实验也验证了各组件的贡献。

相关内容
热门资讯
“一字之变”看治理升级 中国“...
中新网7月4日电(薛凌桥 戴悦 唐雨弦 吴家驹)“中国政府在2026年编制的‘十五五’规划全球瞩目,...
深读河源 | “湖泊+”赋能下...
7月开渔,沉寂数月的万绿湖面再次因鱼的跳跃而沸腾。这场水产丰收的狂欢背后,一条生态产业之路正越走越清...
华农“赤脚院士”罗锡文:半世纪...
文/羊城晚报全媒体记者 陈亮 实习生 杨月华图/华南农业大学提供7月1日,庆祝中国共产党成立105周...
广州地铁十二号线中段顺利实现长...
羊城晚报讯 记者严艺文,通讯员马润韬、陈虎辉报道:近日,在建地铁十二号线中段轨道工程顺利实现长轨贯通...
蓝精灵等比利时九大经典IP齐聚...
羊城晚报讯 记者黄宙辉、王漫琪,通讯员黄淑娟报道:2日,“气泡王国——比利时国宝漫画百年巡礼”展览在...
以食为桥深化对口协作!天河-广...
文、图/羊城晚报全媒体记者 徐炜伦7月2日,天河-广宁非遗美食推介会暨第二届天凝丝丹笋品鉴推广会在广...
中国反兴奋剂中心:游泳运动员王...
据中国反兴奋剂中心网站消息,近期,反兴奋剂中心实施的兴奋剂检查、调查中,游泳运动员王子铭构成兴奋剂违...
广州地铁十三号线二期(鸦岗—天...
文/羊城晚报全媒体记者 严艺文7月3日,广州市交通运输局官网发布通告,根据广州地铁集团有限公司的申请...
排查整治隐患 牢守安全底线——...
新华社北京7月2日电 题:排查整治隐患 牢守安全底线——2026年全国“安全生产月”活动综述新华社记...