谷歌DeepMind革新AI视觉:Gemini3Flash模型让机器“思考、行动、观察”
创始人
2026-01-28 14:32:52
0次
1月27日,谷歌DeepMind团队宣布在Gemini3Flash模型基础上推出“智能体视觉”功能。这一功能通过结合视觉推理与代码执行,模仿人类“思考、行动、观察”循环处理图像,从而确立答案的视觉证据。与传统AI模型相比,Gemini3Flash能够主动调查图像,生成基于事实的最终回复。
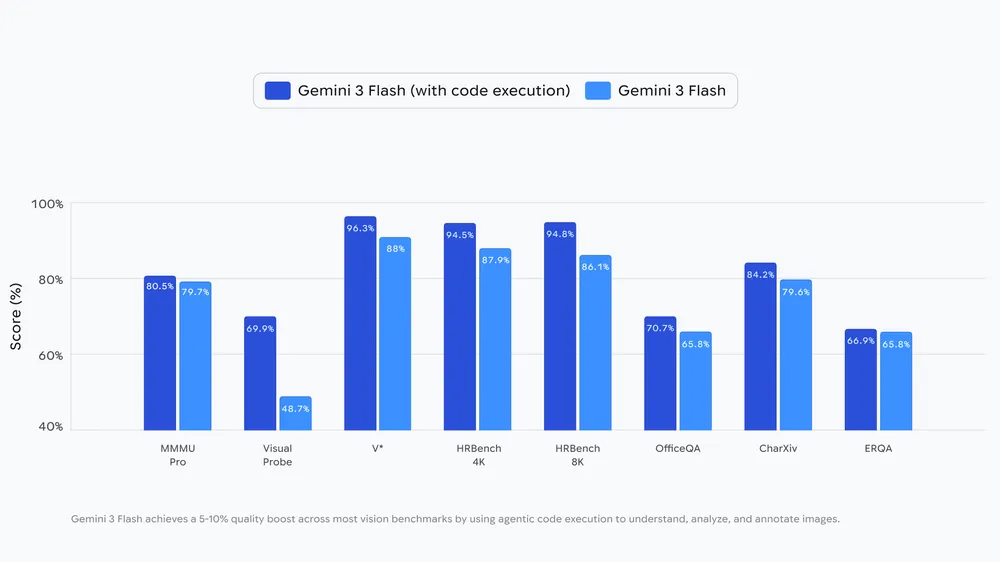
“智能体视觉”功能的核心在于形成“思考-行动-观察”闭环。模型首先分析用户查询和初始图像,制定多步计划;然后生成并执行Python代码来主动操作图像或进行分析;最后,变换后的图像被追加到模型的上下文窗口中,利用更新后的数据和更佳的语境进行二次检查。这一机制让Gemini3Flash在多数视觉基准测试中质量提升了5-10%。
例如,在建筑图纸验证平台PlanCheckS网页链接上,利用“智能体视觉”功能让模型通过代码裁剪并分析屋顶边缘等高分辨率细节,使准确率提高了5%。此外,在处理视觉数学问题时,模型通过编写代码识别原始数据并调用Matplotlib库绘制精确图表,有效解决了大型语言模型在多步视觉算术中常见的“幻觉”问题。

相关内容
热门资讯
别克至境E7两周销量破5000...
5月6日,别克汽车官方宣布,至境E7上市两周累计交付量已突破5000台,其中“有孩家庭”占比超过80...
电竞潮燃“五一”,电竞粤超东莞...
羊城晚报讯 记者陈旭泽报道:5月5日,2026广东省电子竞技超级联赛(以下简称“电竞粤超”)城市巡回...
广东多所高校探索“艺科融通”复...
文/羊城晚报全媒体记者 秦小杰图/受访者提供近日,广东多所专业类高校密集举办系列活动,深入探索艺术与...
两名“红领巾”的跨国相遇!越南...
文/羊城晚报全媒体记者 张小悦图/通讯员 岳青“He is my best friend!(他是我最...
华晨宇直播哭了,发文致歉
4月22日晚,歌手华晨宇发文致歉,在云南举办的火星乐园2.0因不可抗力延期。全文如下:火星乐园2.0...
广州荔湾多宝街道:空间挖潜+数...
文/羊城晚报全媒体记者 梁怿韬 通讯员 成广聚 陈梓佳图/通讯员提供空间狭窄,是地处老城区的广州市荔...
市民反映“广州一高架桥底疑现裂...
4月21日,广州市交通运输部门发布情况核查通报:收到网络反映内环中路电视台处的高架桥疑似裂缝情况后,...
边深蹲边吸氧?广州白云山有了森...
文/羊城晚报全媒体记者 孙牧图/受访单位供图近日,一场别开生面的森林“健身房”暨“爱绿护绿”志愿服务...
以“精度”换“速度”!广州增城...
文/羊城晚报全媒体记者 马灿 通讯员 增宣图/通讯员提供暮春夏至,万物竞发。走进广州增城区,工地上机...
酷!广州这群长者化身无人机飞手...
文/羊城晚报全媒体记者 徐振天图/受访者提供“起飞、悬停、慢慢转向!”4月21日下午,广州市黄村街颐...