Qwen3-TTS多码本模型开源!1.7B性能极致,0.6B效率均衡
创始人
2026-01-22 22:26:02
0次
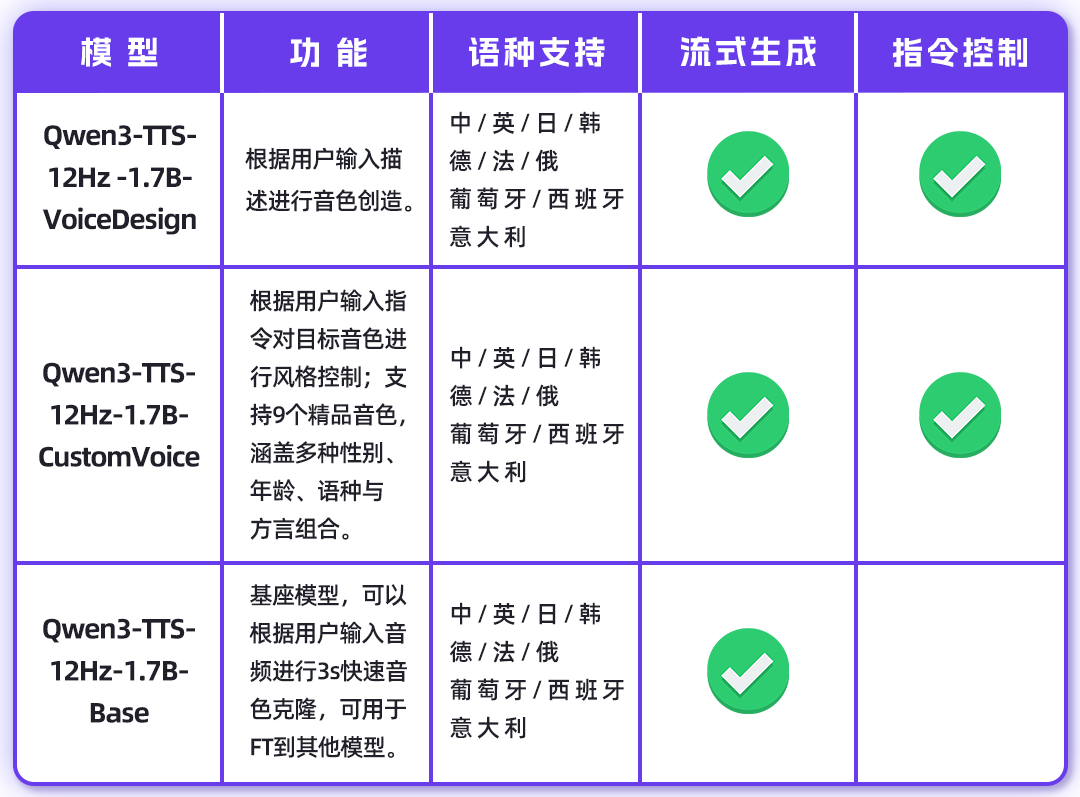
1月22日,千问Qwen微信公众号宣布,Qwen3-TTS多码本全系列模型已开源,提供1.7B和0.6B两种尺寸,其中1.7B模型可提供极致性能,而0.6B模型则在性能与效率之间实现均衡。Qwen3-TTS是一系列强大的语音生成模型,支持音色克隆、音色创造、超高质量拟人化语音生成,以及基于自然语言描述的语音控制,满足开发者和用户的多样化需求。
Qwen3-TTS采用创新的Qwen3-TTS-Tokenizer-12Hz多码本语音编码器,实现了对语音信号的高效压缩与强表征能力,保留了副语言信息和声学环境特征,并通过轻量级的非DiT架构实现高速、高保真的语音还原。该模型采用Dual-Track双轨建模,实现了极致的双向流式生成速度,首包音频仅需等待一个字符。模型覆盖10种主流语言及多种方言音色,具备强大的上下文理解能力,可根据指令和文本语义自适应调整语气、节奏与情感表达,对输入文本噪声的鲁棒性有显著提升。
Qwen3-TTS在音色克隆、创造、控制等方面进行了全面评估,结果显示其在多项指标上都达到了SOTA性能。在音色创造任务上,Qwen3-TTS-VoiceDesign在InstructTTS-Eval中指令遵循能力和生成表现力都整体超越MiniMax-Voice-Design闭源模型,并大幅领先其余开源模型。在音色控制任务上,Qwen3-TTS-Instruct展现出卓越的长语音生成能力,一次性合成10分钟语音的中英词错率为2.36/2.81%。在音色克隆任务上,Qwen3-TTS-VoiceClone在多个测试集上超越MiniMax和SeedTTS,跨语种音色克隆也超越CosyVoice3位居SOTA。


相关内容
热门资讯
华为钱包携手首驱科技,全球首发...
近日,智慧车联产业生态联盟宣布,联盟首个两轮车企成员首驱科技与华为钱包合作,共同打造了全球首个面向两...
马斯克再出手!xAI并入Spa...
5月6日,美国航天公司SpaceX和AI公司xAI的创始人埃隆·马斯克在社交媒体上宣布,xAI更名为...
MG4X纯电SUV盲订将启:5...
5月7日,上汽MG宣布旗下纯电SUV——MG4X将于5月11日开启盲订。MG4X延续了发光LOGO设...
智慧医疗怎样改变我们的就医日常...
文/羊城晚报全媒体记者 刘颖颖 实习生 吕思颖 通讯员 穗卫健宣看病时不知道挂哪个科、看不懂检查报告...
票根串起消费链 文旅延伸新玩法...
文/羊城晚报全媒体记者 刘星彤 通讯员 粤文旅宣5月2日,“五一”假期第二天,广东各地出游热度继续攀...
假期聚餐后上腹绞痛?别大意!可...
“五一”假期亲友相聚,美食盛宴必不可少,一顿胡吃海塞后,不少人把身体的不适都归为“消化不良”。但如果...
五一假期最后两天我国降水较少 ...
央视网消息:据中国天气网消息,五一假期最后两天(5月4日至5日),我国大部降水较少,利于假期返程,华...
电竞粤超首场城市巡回赛在河源收...
羊城晚报全媒体记者陈旭泽报道:5月3日,广东省首届电子竞技超级联赛(以下简称“电竞粤超”)首场城市巡...
方程豹4月销量飙升190%,钛...
5月7日,方程豹汽车公布4月销量数据,单月销量达到29138台,同比增长190.2%,环比增长12....
广货行广交|专注“头等生意” ...
广东揭阳,一座以制造业为根的城市,在传统产业转型升级的过程中,如何让老产业焕发新机,让老外在广交会上...