AI对话新突破!StepAudio2.5Realtime模型让机器更懂你
创始人
2026-05-09 10:42:51
0次
5月9日,阶跃星辰发布了新一代实时语音大模型StepAudio2.5Realtime,并已全面上线。该模型致力于提供更具“活人感”的AI对话体验,通过副语言感知、人设自定义与对话能力三个方向的技术升级。StepAudio2.5Realtime的核心优势在于其对副语言信息的处理能力,能够解读语调、语速、停顿等非文字表达方式,从而感知对话者的情绪状态与潜在意图,动态调整回应的语气与策略。
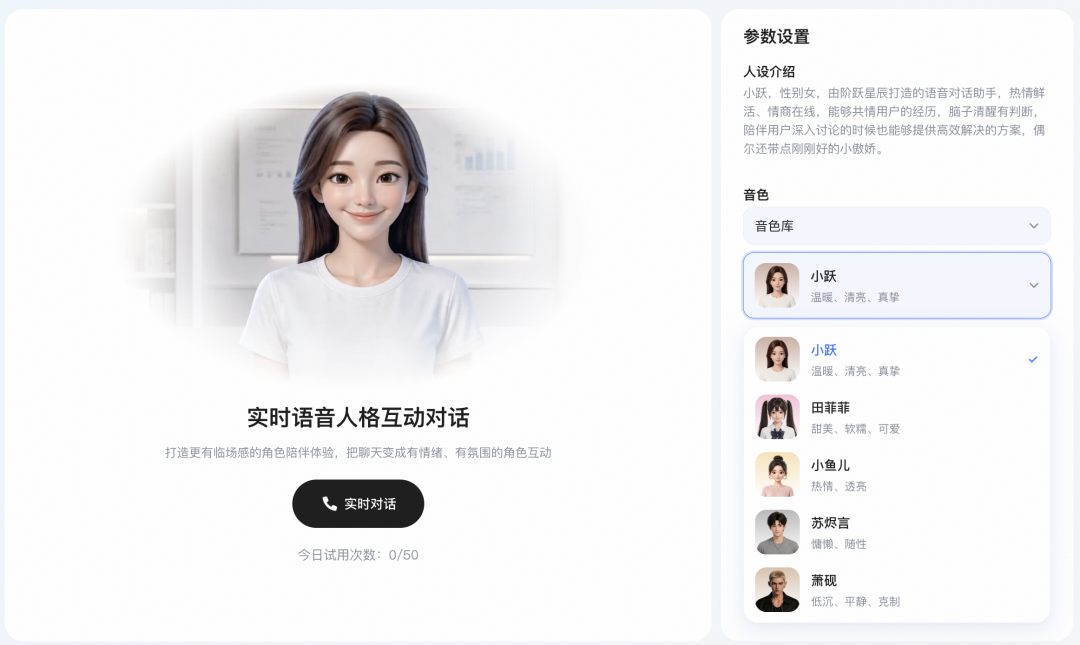
在人设灵活性方面,StepAudio2.5Realtime允许开发者通过API对AI角色进行精细化调节,包括性格特质、背景经历等。这一能力基于超过10,000个高质量原生人设,通过算法裂变生成的百万级人设特征矩阵,并结合海量真实场景对话语料训练而来。开发团队还针对深度角色扮演中的“人设崩塌”问题进行了专门的RLHF对齐优化,确保模型在极端情境下保持角色一致性。
StepAudio2.5Realtime在整体对话能力上强调智商与情商的双重提升,能够深度理解复杂语义、应对交流场景,并灵活调用多领域知识提供深度对话体验。官方发布的2026年4月评测数据显示,该模型在五个测试维度中均位列第一,主观评测得分80.41,语音问答基准得分79.80,约为GPT-Realtime-1.5的1.5倍。

相关内容
热门资讯
日系电动车拥抱中国技术,本田丰...
近日,日系电动汽车在华销售策略出现转变,开始依赖中国零部件和电动汽车技术。本田汽车社长三部敏宏在访问...
比亚迪海外销量激增,品牌架构大...
7月15日,比亚迪宣布对海外品牌架构进行调整,将王朝与海洋系列整合为“比亚迪品牌”,腾势与方程豹合并...
阿里巴巴发布Qwen-Audi...
7月15日,阿里巴巴宣布实时语音交互对话模型Qwen-Audio-3.0-Realtime正式发布。...
长城汽车上半年净利润大降近六成...
7月15日,长城汽车发布了2026年半年度业绩预告报告,预计归母净利润在23.50亿元至26亿元之间...
宝马奔驰奥迪销量下滑,国产新能...
7月15日,国内豪华燃油车市场面临重大挑战,宝马、奔驰、奥迪三大品牌销量集体下滑。自5月起,各大4S...
MacWhisper 14.0...
昨日(7月14日),独立开发者乔迪·布鲁因宣布推出MacWhisper 14.0更新,该更新专注于提...
雷诺吉利合资发布D20甲醇增程...
7月14日,雷诺集团与吉利合资的霍尔斯动力公司发布了D20甲醇增程器动力总成,专为增程式电动汽车设计...
和机器人打羽毛球你能赢吗?欢迎...
你有日常打羽毛球的习惯吗?你的球技可以打赢机器人吗?记者7月14日从广州市海珠区获悉,总部设于该区的...
广东公布暑期档大动作 一张票根...
羊城晚报全媒体记者 李丽2026年暑期档已拉开大幕。据国家电影局发布的信息,今年暑期档有近80部影片...
老乡鸡五次折戟资本市场 202...
近日,老乡鸡1月8日递交港交所的招股书届满6个月正式失效。这已是老乡鸡五年间第五次冲击资本市场失败—...