智能体推理新突破!DualPath框架提升吞吐量近2倍
创始人
2026-02-27 10:11:00
0次
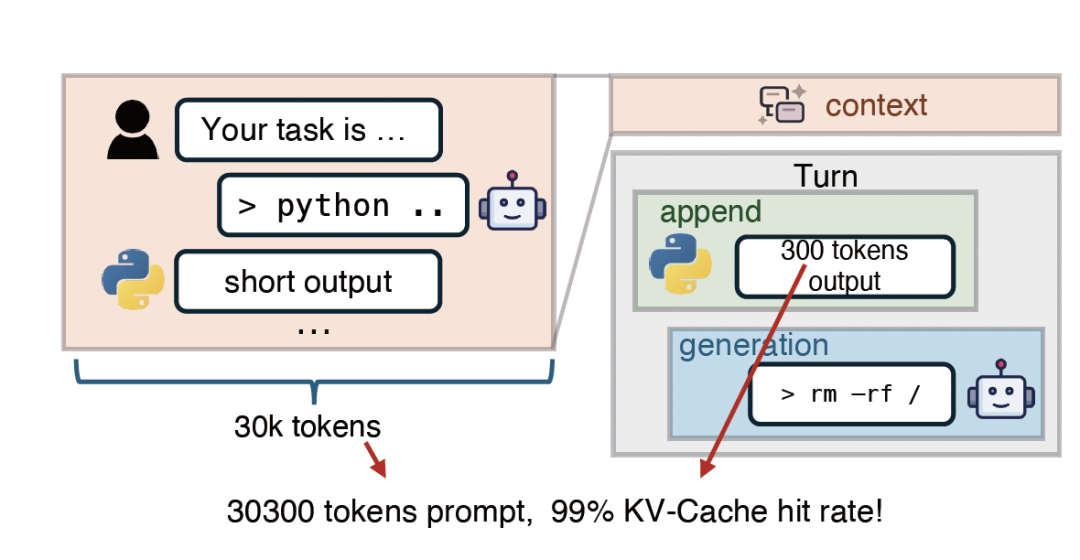
近日,DeepSeek与北京大学、清华大学合作,在ArXiv上发表了一篇新论文,介绍了一个名为DualPath的智能体推理框架。该框架旨在解决长文本推理场景下的I/O瓶颈问题,通过优化KV-Cache的加载速度,确保计算资源不被存储读取拖累。DualPath改变了传统的存储至预填充引擎的单路径加载模式,引入了存储至解码引擎的第二条路径,利用解码引擎闲置的存储网卡带宽读取缓存,并配合高速计算网络RDMA将其传输至预填充引擎,实现了集群存储带宽的全局池化与动态负载均衡。
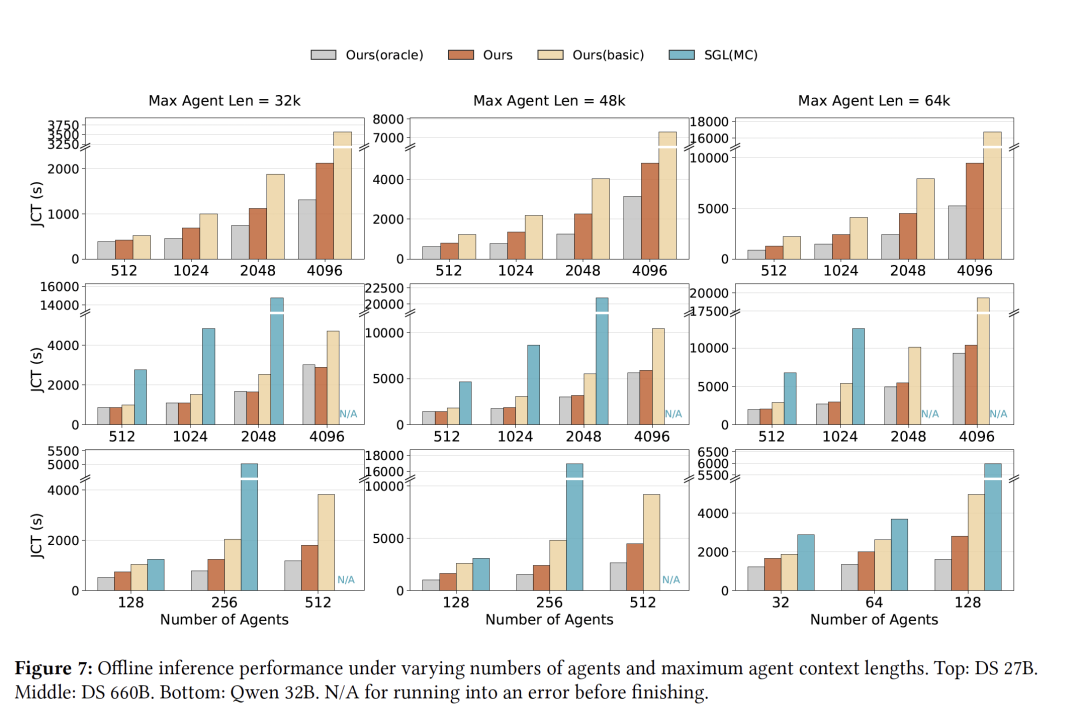
DualPath的核心洞见是KV-Cache的加载不必以预填充为中心,而是可以先加载到解码引擎中,再通过RDMA网络传输至预填充引擎。这种设计允许系统在两条路径间动态分配负载,释放了原本闲置的解码侧存储网卡带宽,构建起一个全局可调度的存储I/O资源池。在660B规模的生产级模型实测中,DualPath显著提高了离线推理吞吐量和在线服务吞吐量,同时优化了首字延迟和Token间生成速度。
DualPath的架构包括推理引擎、流量管理器和中央调度器,分别负责管理GPU、处理数据传输和实时决策请求路径。该框架通过自适应请求调度和严谨的流量隔离机制,在不增加硬件成本的前提下,大幅提升了智能体LLM推理系统的效率。

相关内容
热门资讯
奥迪E7X纯电SUV亮相北京车...
2026年4月24日,奥迪与上汽合作的豪华新能源汽车品牌AUDI在2026北京车展上发布了其首款纯电...
吉利银河A7EM/A7EV双车...
今日,吉利汽车发布了2026款银河A7EM/A7EV双车系列,标志着品牌在新能源汽车领域的进一步拓展...
比亚迪2026款夏露营改装版亮...
今日,2026北京车展上,比亚迪王朝网旗下中大型旗舰MPV——2026款夏带来重磅惊喜,官方定制露营...
DeepSeek-V4模型震撼...
4月24日,DeepSeek公司宣布推出其新一代基础模型DeepSeek-V4,该模型已在官网、官方...
比亚迪大唐EV预售开启,950...
4月24日,比亚迪王朝网旗下全新全尺寸旗舰SUV大唐EV正式开启预售,预售价25万元至32万元。新车...
华为问界M6上市15分钟订单破...
4月22日,华为常务董事余承东宣布,搭载鸿蒙智行系统的问界M6汽车上市15分钟内,大定订单已突破10...
千里科技发布AI战略,2027...
4月22日,千里科技在北京举办了AI战略暨产品发布会,宣布了其“AI+车”战略的最新成果,并探讨了A...
越南青年来华“红色研学之旅”广...
文、图/羊城晚报全媒体记者 张小悦 通讯员 岳青4月11日至13日,由共青团中央主办,中央团校、共青...
广州南沙:智能育秧显优势,稻苗...
清风催新绿,春耕正当时。当许多地方仍在沿用传统手工育秧方式时,广州南沙多家育秧中心已率先引入智能化生...
把植物新品种繁殖换个名销售,法...
故事梗概2023 年4月,A公司发现B某、C公司及D公司(法人代表B某)大量对外销售、宣传销售被诉侵...