蚂蚁技术研究院发布100B参数扩散语言模型LLaDA2.0,性能超越自回归模型
创始人
2025-12-12 16:11:58
0次
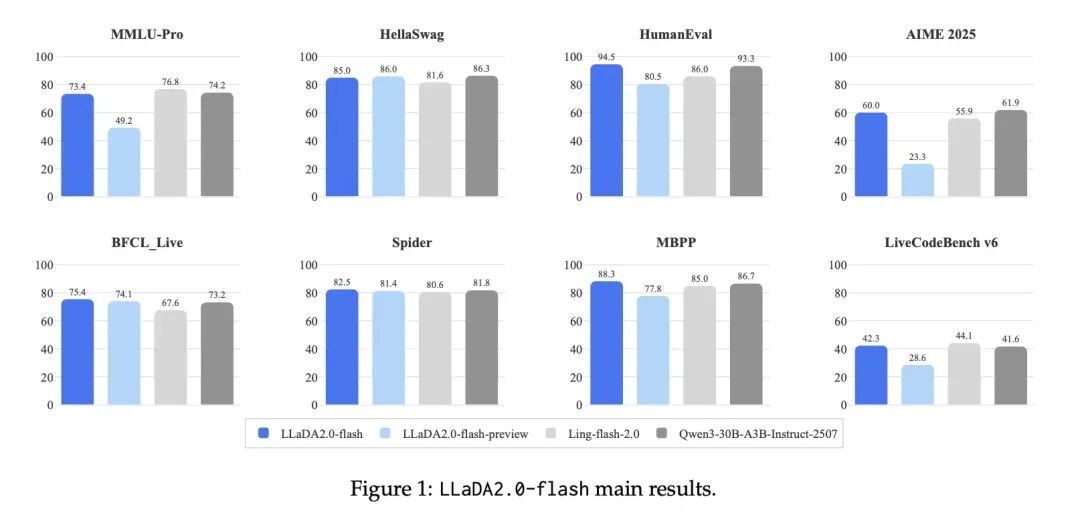
12月12日,蚂蚁技术研究院宣布推出LLaDA2.0系列离散扩散大语言模型(dLLM),并公开了背后的技术报告。LLaDA2.0包含16B(mini)和100B(flash)两个版本,将Diffusion模型的参数规模首次扩展到了100B量级。该模型不仅打破了扩散模型难以扩展的固有印象,更在代码、数学和智能体任务上展现出了超越同级自回归(AR)模型的性能。
LLaDA2.0通过创新的Warmup-Stable-Decay(WSD)持续预训练策略,能够无缝继承现有AR模型的知识,避免了从头训练的高昂成本。结合置信度感知并行训练(CAP)和扩散模型版DPO,LLaDA2.0在保证生成质量的同时,利用扩散模型的并行解码优势,实现了相比AR模型2.1倍的推理加速。蚂蚁技术研究院在多个维度对模型进行了评估,结果显示LLaDA2.0在结构化生成任务(如代码)上具有显著优势,并在其他领域与开源AR模型持平。
LLaDA2.0的模型权重(16B/100B)及相关训练代码已在Huggingface开源。
相关内容
热门资讯
专访资深政法记者刘海陵:笔锋铸...
刘海陵的新闻人生,是改革开放的生动缩影,是法治进步的忠实见证,更是新闻理想的永恒传承。世纪之交,香江...
38岁身家过亿房地产老总家中遭...
南京市江宁区一身家过亿的房地产老总刘某,在家中遭人杀害,事发16年后,这处“凶宅”于5月7日进行第二...
粤超第三轮球票今日14时开始预...
随着“五一”小长假结束2026年冠旭电子cleer·广东省城市足球超级联赛(粤超)21城全部亮相5月...
记者帮|广州50万粉“捡瓶小狗...
昨日,羊城晚报“记者帮”报道《广州50万粉丝“捡瓶小狗”,疑被“毒狗团伙”盯上,目前只能被迫困在家中...
彩旗飘飘,锣鼓喧天!广州天河石...
农历三月廿三是传统的妈祖诞民俗节日,又叫天后诞,石牌人称娘妈诞。5月9日上午,广州市天河区石牌村开启...
【在希望的田野上】新技术新装备...
央视网消息(新闻联播):农忙时节,各地因地制宜,广泛采用新技术、新装备、新方法节本增效,为丰产丰收打...
老挝官员:老中铁路不仅象征着两...
老挝官员:老中铁路不仅象征着两国友好关系,也为两国人民带来巨大红利
视频丨日本有识之士:高市政权种...
日本高市早苗内阁推动的设立“国家情报局”相关法案8日在日本参议院全体会议进入审议阶段。日本有识之士认...