美团开源6B参数图像生成模型,文生图与编辑能力惊艳提升!
创始人
2025-12-08 10:29:57
0次
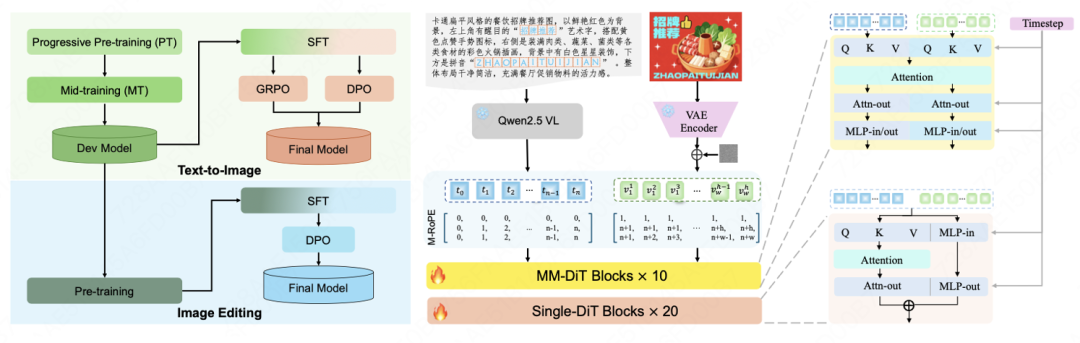
今日,美团LongCat团队宣布正式发布并开源了图像生成模型LongCat-Image。该模型以6B参数规模,在文生图和图像编辑的核心能力上接近更大尺寸模型的效果。LongCat-Image采用文生图与图像编辑同源的架构设计,并结合渐进式学习策略,实现了指令遵循精准度、生图质量与文字渲染能力的高效协同提升,尤其在单图编辑的可控性和文字生成的汉字覆盖度方面表现突出。
LongCat-Image在图像编辑领域的多个重要基准测试中达到开源SOTA水平,其性能突破的背后是一套紧密协同的训练范式和数据策略。模型基于文生图Mid-training阶段模型进行初始化,并采用指令编辑与文生图多任务联合学习机制,深化对复杂多样化指令的理解。此外,通过预训练阶段的多源数据及指令改写策略,以及SFT阶段引入人工精标数据,实现了指令遵循精准度、泛化性和编辑前后视觉一致性的共同提升。
针对中文文本渲染的行业痛点,LongCat-Image通过课程学习策略提升字符覆盖度和渲染精准度。预训练阶段基于千万量级合成数据学习字形,覆盖通用规范汉字表的8105个汉字;SFT阶段引入真实世界文本图像数据,提升在字体、排版布局上的泛化能力;RL阶段融入OCR与美学双奖励模型,进一步提升文本准确性与背景融合自然度。通过对prompt中指定渲染的文本采用字符级编码,大幅降低模型记忆负担,实现文字生成学习效率的跨越式提升。


相关内容
热门资讯
阿维塔07L豪华SUV亮相:华...
5月10日,工信部第407批《道路机动车辆生产企业及产品公告》新产品公示中,阿维塔科技的全新车型阿维...
【“中国游记”第二季㉞】过境免...
在北京,有一条藏着近千年文脉的传奇中轴线。7.8公里纵贯古今——永定门的庄重、故宫的恢弘、天坛的灵秀...
【国际3分钟】80年后,日本军...
2026年是东京审判开庭80周年,然而日本部分势力仍在歪曲侵略历史、为战犯翻案,更借“安全威胁”推动...
奋斗的青春 | 张海光:一个农...
央广网大连5月9日消息(记者 易博闻)在大连海洋大学的实验水池边,总能看到一个蹲在地上、满手油污的身...
鸿蒙智行尊界S800高定版亮相...
5月10日,工信部最新一批新车申报目录中,鸿蒙智行尊界S800GrandDesign高定版亮相,定位...
游客称女士进入河南博物院卫生间...
近日,有游客发布视频“吐槽”河南博物院洗手间,女士进入洗手间会路过男士小便池,担心存在隐私被泄露的风...
记者帮丨广州一省道路口变露天车...
“高架桥惊现神秘停车区,车停得比桥还稳……”近日,有网友在社交媒体发布消息,在广州科学城路口附近的一...
感恩母爱、健康睡眠,广州荔湾中...
5月9日上午,广州市荔湾中心医院花地湾院区门诊大厅内,一场“感恩母爱 健康睡眠”母亲节主题健康科普及...
龙舟侧翻、游客落水?飞行救生圈...
5月9日,聚焦汛期安全防控与夏季水上活动风险特点,广州市公安局在海珠湿地公园开展水上应急救援联合演练...
新华社权威快报|增长14.9%...
海关总署5月9日发布数据今年前4个月我国货物贸易进出口总值16.23万亿元同比增长14.9%其中,出...