英伟达TiDAR技术:AI文本生成速度提升5倍!
创始人
2025-12-02 15:30:55
0次
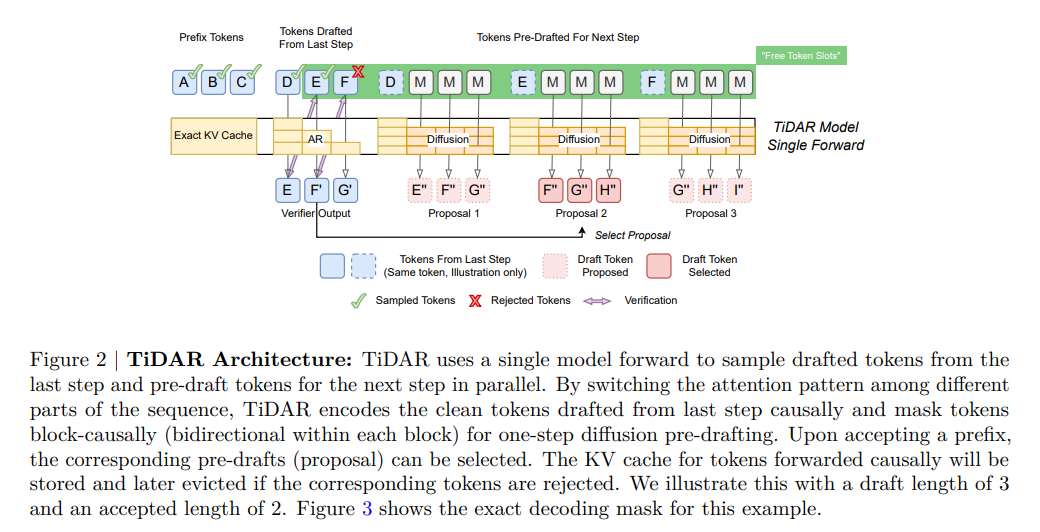
12月2日,科技媒体Tom'sHardware报道了英伟达最新论文中介绍的TiDAR新型AI解码方法。TiDAR结合了自回归和扩散模型机制,通过利用GPU的“空闲槽位”加速文本生成。自回归模型按顺序生成文本,而扩散模型则一次性生成多个可能的词。TiDAR的核心在于在不牺牲质量的前提下,通过单步生成多个Token来提升响应速度并降低GPU运行时长。
TiDAR技术原理上创新性地训练单个Transformer模型同时执行自回归“下一词预测”和基于扩散的“并行起草”。它通过结构化的注意力掩码将输入分为三个区域:前缀区、验证区和起草区。这种设计让模型在利用扩散头并行起草新Token的同时,还能通过自回归头验证这些草稿,确保了KV缓存的结构有效性。
研究团队基于Qwen系列模型进行了测试。在HumanEval和GSM8K等基准测试中,TiDAR的准确率与基准模型持平甚至略有提升。在速度方面,15亿参数版本的TiDAR模型实现了4.71倍的吞吐量增长;而80亿参数版本的表现更为抢眼,吞吐量达到了Qwen3-8B基准的5.91倍。这表明TiDAR能有效利用GPU的显存带宽,在不增加额外显存搬运的情况下生成更多Token。尽管实验数据亮眼,TiDAR目前仍面临规模扩展的挑战,未来将在更大规模的模型上进行验证。

相关内容
热门资讯
昆仑万维方汉:豆包手机无渠道必...
5月8日,昆仑万维董事长方汉在接受凤凰网财经采访时对豆包手机的前景表示悲观。方汉认为,由于豆包手机缺...
昆仑万维CEO:AI时代白领最...
5月7日,昆仑万维董事长兼总经理方汉在接受凤凰网财经《封面》采访时表示,在AI时代,普通人应多使用A...
赛力斯动力携手一汽铸锻,开创“...
5月10日,赛力斯集团执行董事、副总裁康波在重庆广电第一眼的采访中分享了赛力斯动力工厂的最新进展。康...
中国汽车零部件崛起:美市场超4...
近日,中国汽车产业在全球市场的影响力显著提升,中国车企已跃居全球销量冠军。专家西蒙指出,海外车企和零...
宝马2027年推中国特供长轴距...
近日,北京国际车展上宝马品牌多款新车重磅首发,其中三款全新车型成为焦点。宝马7系/i7改款车型即将登...
粤菜,分轮点菜吃更爽 | 茶楼...
朋友聚会时点菜,你会不会把菜一股脑点完,就赶紧进入开吃、聊天环节?其实,如果一大帮人聚餐,把要吃的完...
今晚11时起,广州荔湾蓬莱路部...
为确保车行道路面沥青刨铺工程以及标注交通标线顺利推进,经有关部门批准,广东省第一建筑工程有限公司将对...
晚霞落“镜”中 稻乡入画来
晚霞映照下的富锦市万亩水稻公园(5月9日摄,无人机照片)。时下,黑龙江省三江平原陆续进入水稻插秧时节...
蓝厅观察丨自卫队右倾化 日本恐...
2026年美菲“肩并肩”联合军事演习自4月20日起在菲律宾多地举行。这场演习从一开始就引发了菲律宾民...
单月出口表现强劲 中国外贸延续...
海关总署5月9日发布数据,今年前4个月,我国货物贸易进出口总值16.23万亿元,同比增长14.9%,...